
Feb 23, 2026
Margaret Corvid (Social Team @ Yupp)
Bhabishya Kumar (Engineering @ Yupp)
When AI sees a word that doesn’t exist, what does it see instead?
We hid the word HOPE inside a pattern of chevron stripes and asked the strongest AI vision models to read it. The image, shared by a Yupp.ai contest finalist, Subhobhai , encodes its letters purely through orientation contrast: regions where diagonal stripes angle in opposite directions from the surrounding pattern. No color difference, no brightness difference – just the direction of the lines.
Zero of the models we tested correctly interpreted it. Claude said “LOVE.” GPT said “TEST.” Grok said “GROK.” Yet, a Gabor filter – a classical computer vision technique from 1991 – trivially decoded what every frontier vision model that we tested with could not. Once the orientation contrast was converted to simple brightness contrast, the same set of models read HOPE instantly.
The results were clean and dramatic: no frontier vision model could read a word encoded purely through orientation contrast, yet a 1991 Gabor filter decoded it instantly. But they left an uncomfortable question unanswered.
HOPE is a common English word. When models read it correctly after Gabor preprocessing, were they actually seeing the letters – or guessing the most likely four-letter word from partial visual cues? The dominant wrong answer across every test was LOVE: another common four-letter word, exactly the kind of thing a language model would predict for “hidden word in an image” without needing to be able to understand or interpret anything at all.
We needed a word with fewer language priors to lean on. A word so uncommon that no model would stumble onto it by guessing.
We needed BOOP.

BOOP, drawn in diagonal lines.
What is BOOP? It originates in scat singing within jazz and the famous cartoon vixen, Betty Boop. More recently, BOOP refers to the notion of beholding an animal that is so adorable that you press its nose and say the word "boop". The OED has the verb "boop" (gentle tap, especially on the nose, as a gesture of affection) from as early as the 1940s, with the noun form appearing around 2002. The internet meme version – "boop the snoot" – really took off around 2010-2012 with Reddit's r/boop and Buzzfeed listicles of animals getting nose-tapped. In short, Boop is well in the vernacular of the internet but is also recent enough that it could be less likely to appear prominently in training data, making it a useful instrument to explore model guessing profiles when they incompletely decipher an image.
The Setup
We generated three new orientation-contrast illusion images via AutoCAD: BOOP, PIPE, and LIFE. Each encodes its word the same way as the original HOPE – through stripe orientation alone.
At baseline, with no hints, we ran all three across 14 frontier vision models on Yupp, an AI evaluation platform offering over 900 AIs to everyone to use for free in exchange for honest feedback on model responses. The results revealed a striking gradient:
LIFE, a high-frequency English word, was read correctly by 3 out of 14 models. PIPE, a medium-frequency word, scored 0 out of 14 – but both Gemini tiers answered POPE, recognizing P_PE and filling in what it inferred as the most probable English completion. BOOP, low-frequency and nonsense-adjacent, scored 0 out of 14 with no near-misses at all. Pure noise.
Perhaps, the more guessable the word, the better models perform: not because they see more clearly, but because language priors have more to work with.
We then ran BOOP through three experimental treatments – prompt coaching, resolution scaling, and Gabor preprocessing – to test exactly where vision ends and language begins.
Full results: BOOP Across All Treatments
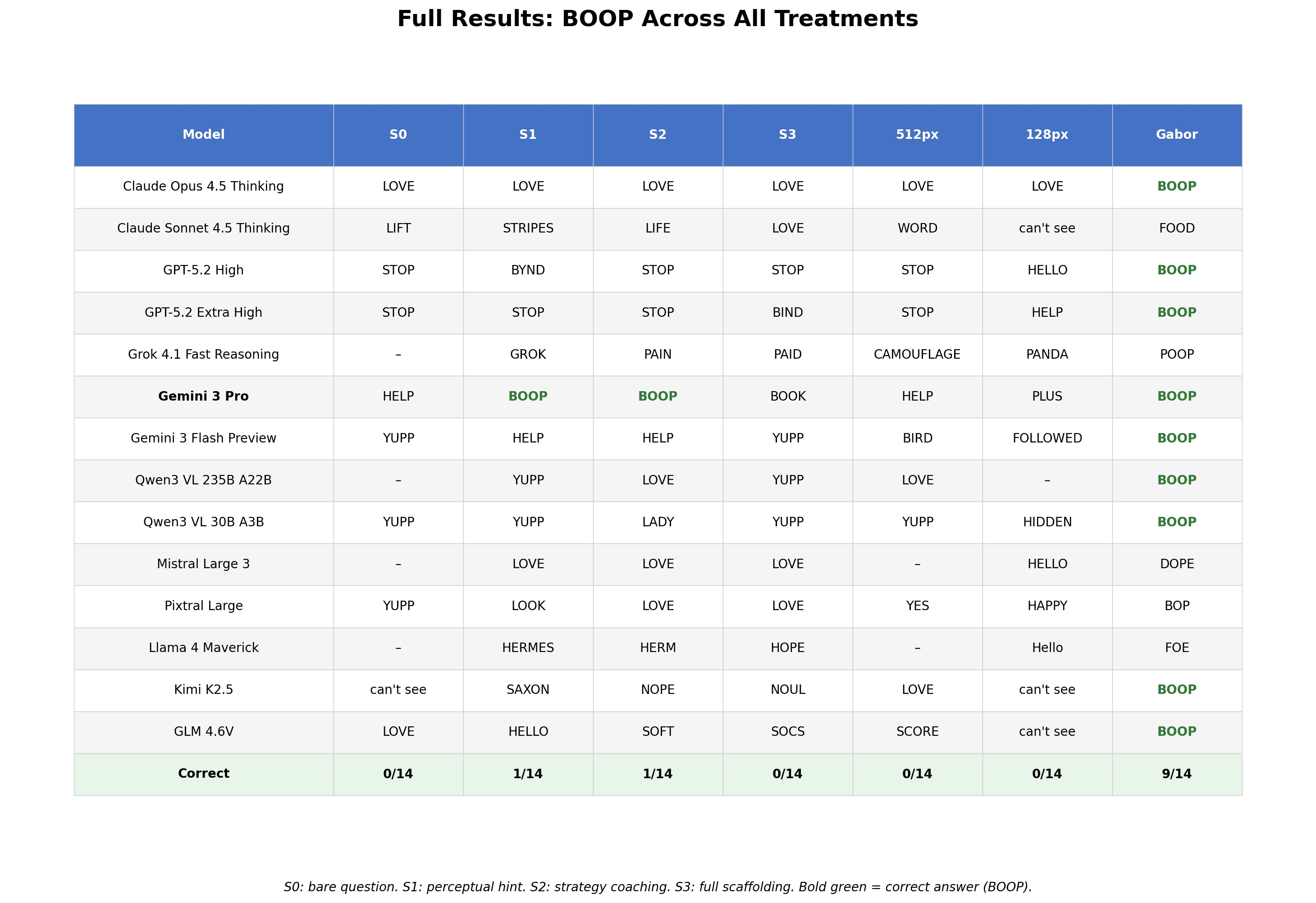
S0: bare question. S1: perceptual hint. S2: strategy coaching. S3: full scaffolding. Bold green = correct answer (BOOP).
The Coaching Experiment
Could better instructions close the gap? We tested four prompt levels, from a bare question (“What word is hidden in this image?”) to full scaffolding that spelled out exactly how chevron stripes encode letter shapes through orientation contrast.
At Level 0, no model read BOOP. At Level 1, with a basic perceptual hint about stripe direction, one model cracked it: Gemini 3 Pro. At Level 2, with strategy coaching, Gemini held its correct answer. Then at Level 3, with maximum scaffolding, Gemini answered BOOK.
B-O-O-K. Three letters correct, one substituted. Its chain of thought confirms what happened: the model explicitly examined candidate final letters including P – the correct answer – and rejected it in favor of K, producing a real English word instead of the correct uncommon one.
This is an inverted U-curve caught in the act. Moderate scaffolding enabled genuine visual processing: the model extracted the letterforms and read BOOP correctly. Maximum scaffolding activated the language system so aggressively that it overrode the visual evidence, “correcting” an accurately-seen P into a K to make BOOK. You can coach an AI to see. Coach too much and its language brain takes over.
The other models tell the same story from different angles. Claude Opus 4.5 answered LOVE at every single level – S0 through S3, unwavering. Not misreading. Not reading at all. Generating the most statistically probable completion for “hidden word” and committing to it across every prompt condition with absolute confidence.
GPT-5.2 Extra High anchored on STOP across the first two prompt-softening levels, then at Level 3 shifted to BIND – its chain of thought systematically working through BIRD, BIND, BOLD, and BLOG, all real English words starting with B, before committing. The scaffolding didn’t improve its vision. It just gave the language system more to work with.
The Resolution Test
Recent work by Li, Cai, and Wang (2025) showed that downscaling hidden-content images to low resolution can unlock VLM accuracy on their HC-Bench benchmark. The explanation is elegant: fine visual noise averages out while the macro-pattern that forms hidden text survives as blocks of different brightness.
We downscaled BOOP to 512 and 128 pixels. Zero out of fourteen read the word correctly at both resolutions. The reason: orientation-contrast illusions encode information through stripe angle, not brightness. When downscaling averages the pixels, forward-leaning and backward-leaning stripes converge to the same uniform gray. The signal doesn’t simplify – it vanishes. Humans can still read BOOP at 512 pixels. The models cannot.
At 128 pixels, the hallucinations became extraordinary. Grok 4.1 described a bamboo grove with sunlight filtering through leaves and carefully traced the word PANDA. GPT-5.2 Extra High spent 314 seconds – over five minutes – cycling through eighteen candidate words before committing to an answer. Five minutes of systematic, articulate reasoning applied to a visual task it never actually performed. These aren’t misreadings – they’re complete narrative constructions, elaborate justifications for answers that have no connection to the image content.
The Gabor Experiment
Gabor filter banks – orientation-tuned filters that respond selectively to stripes at specific angles – have been the standard method for texture segmentation since Jain and Farrokhnia’s foundational 1991 work. We applied a filter bank tuned to the two stripe orientations present in the image (45° and 135°), converting the invisible orientation contrast into visible brightness contrast.
Nine out of fourteen models read BOOP correctly. The same pattern as the original HOPE experiment – classical computer vision trivially decodes what modern VLMs cannot – but with fourteen models instead of three, and with five failures that reveal something the HOPE experiment couldn’t show us.
Four of the five wrong answers are real English words.
Grok 4.1 described B-O-O-P in its analysis – correctly identified all four letters in the grid – then announced the hidden word was POOP, claiming to have traced it through “a continuous path.” It saw the correct answer and its language system overwrote it with a more common word.
Claude Sonnet saw the letter shapes but misidentified B as D and P as F, then rearranged these into FOOD. Mistral saw E-D-O-P and anagrammed it to DOPE. Pixtral, unable to fully resolve the letterforms, hedged between EOP and BOP. Llama saw E-O-O-F and, unable to form a word, settled on FOE. In each case (except for that of Pixtral), the model’s language system took partially-processed or correctly-processed visual information and “corrected” it toward the nearest common English word – even when the right answer was sitting right there.
The Gabor experiment illustrates the pattern from both directions. The nine models that succeeded confirm that the visual information was always in the image – a 1991 technique makes it trivially accessible to the same vision models we had tested earlier. Four out of the five that failed confirm that the bottleneck isn’t vision alone. Even when you do the perceptual work for them, language priors still fight to override what the model sees.
What BOOP Reveals About Model Intelligence
Andrej Karpathy popularized the term “Jagged Intelligence” to describe AI’s uneven capability profile. The concept derives from work by Dell'Acqua, Mollick, and colleagues at Harvard Business School and Wharton, who described a “jagged technological frontier” – tasks that seem similarly difficult to humans fall on completely different sides of the capability boundary. This echoes a much older observation in computer science. In 1988, Hans Moravec noted that the tasks easiest for humans – seeing, moving, recognising faces – were hardest for machines, while abstract reasoning came comparatively cheaply. What was true of classical AI turns out to be true of its successors: the frontier is still jagged, the gaps just fall in different places.
The BOOP experiment catches this unevenness in the act.
The HOPE illusion showed a case of vision models unable to perform orientation-based figure-ground segmentation. BOOP shows us why the failure matters: when a model cannot extract visual information, it doesn’t necessarily report uncertainty – it can hallucinate, using language priors from training data to fill in the gap. And when it can extract visual information, language priors may still override the evidence, substituting probable words for correct ones.
The inverted U-curve is another key finding. Gemini 3 Pro demonstrates that visual processing of orientation contrast is possible for at least some architectures. But language priors, once activated, compete with – and can defeat – genuine vision. The model saw BOOP and wrote BOOK. Grok saw BOOP and wrote POOP. The visual system got it right. The language system “corrected” it.
This has implications beyond optical illusions. Any real-world task where visual evidence conflicts with linguistic expectations – unusual text in images, unfamiliar objects in expected contexts, data that contradicts common patterns – sits in this same territory. The models we tested don’t just fail to see. They see, and then unsee, replacing what’s actually there with what they expect should be.
The word BOOP, with no language prior to lean on, strips away the safety net that let HOPE's results remain ambiguous. And in doing so, it reveals what is, ironically, a deeply human characteristic of these AI models. Humans don’t see with our eyes alone. As Ebbinghaus argued, meaningless stimuli are useful because real words trigger semantic priors that can override raw perception. Wolfe’s MIT demo with nonsense syllables (fip, dut, varl…) makes the same point: when meaning is available, the system reaches for it – whether or not it was ever really there. These vision models don’t just fail to see. They often see with their vocabulary – and, in a quieter way, so do we.
References
Jain, A.K. & Farrokhnia, F. (1991). "Unsupervized Texture Segmentation Using Gabor Filters." Pattern Recognition, 24(12), 1167–1186.
Rostamkhani, M., Ansari, B., Sabzevari, H., Rahmani, F. & Eetemadi, S. (2024). "Illusory VQA: Benchmarking and Enhancing Multimodal Models on Visual Illusions." Spotlight, Multimodal Algorithmic Reasoning Workshop, NeurIPS 2024.
Fu, X., Hu, Y., Li, B., Feng, Y., Wang, H., Lin, X., Roth, D., Smith, N.A., Ma, W.-C. & Krishna, R. (2024). "BLINK: Multimodal Large Language Models Can See but Not Perceive." ECCV 2024.
Vo, A., Nguyen, K.-N., Taesiri, M.R., Dang, V.T., Nguyen, A.T. & Kim, D. (2026). "Vision Language Models Are Biased." ICLR 2026.
Luo, T., Cao, A., Lee, G., Johnson, J. & Lee, H. (2025). "ViLP: Probing Visual Language Priors in VLMs." ICML 2025.
Li, S., Cai, Y. & Wang, Y. (2025). "SemVink: Advancing VLMs' Semantic Understanding of Optical Illusions via Visual Global Thinking." arXiv:2506.02803.
Wolfe, J. (2004). "Memory: What Do You Remember?" Lecture 7, MIT 9.00 Introduction to Psychology, Fall 2004. MIT OpenCourseWare. (Demonstrating principles from Ebbinghaus, H. (1885), Über das Gedächtnis.)





